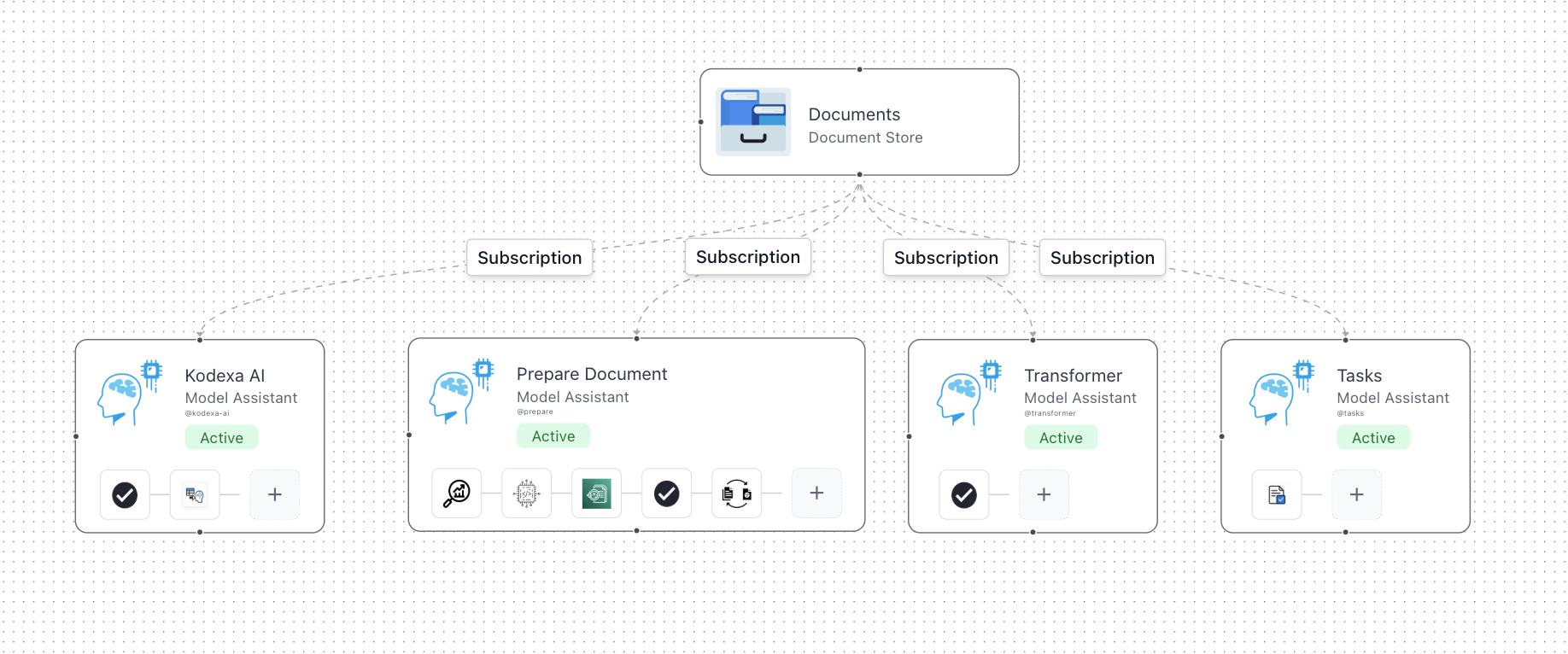
The Data Extraction Starter is a pre-built project template that you can use to get started with Kodexa. It is a great way to get started with Kodexa and can be used to extract data from a wide range of documents.
The default data flow is pre-configured with everything needed to get started.
However, often you will want to add to the data flow. A typical example is being able to publish to external
systems based on the completion (or failure) of a document.In order to do this we will walk through how to create two new models, and show were to add them
to the data flow.
In order to publish success we can create a very simple model and add it to the Task Assistant.You can simply create a new model and add it to the Task Assistant. See the Python Modules guide for how to create an inference module.Once you have created your model you can then add it to the Task Assistant at the end.In the code you can then get the information from the document and publish it to an external system.
def infer(document: Document, project: ProjectEndpoint, pipeline_context: PipelineContext, assistant: Assistant): # Add the logic to allow you to publish a successful document return document
For publishing the failure we would usually use a scheduled event model, the reason for this is that we often want to
defer publishing failures in case we are having a problem in processing.One thing we want to be aware of is that we need to know, in Kodexa, if we have published the failure to the external system.This can be done by adding a label to the document.This means we would create an event handler module that runs every 10 minutes. See the Event Handling guide and the Python Modules guide for details.Once you have created your model you can then add it to the Schedule Assistant at the end.In the code you can then get the information from the document and publish it to an external system.
def handle_event(event: BaseEvent): logger.info(f"Handle event called with event: {event.type}") if event.type == "scheduled": client = KodexaClient() document_store: DocumentStoreEndpoint = client.get_object_by_ref("store","my-org/store-slug") failed_document_families = document_store.stream_filter("documentStatus.slug:'failed' and not exists(labels.label('published-failure'))") for failed_document_family in failed_document_families: # Add the logic to publish the failure to the external system logger.info(f"Publishing failure for document family: {failed_document_family.path}") # Then add a label to the document so we don't pick it up again failed_document_family.add_label("published-failure")
⌘I
Assistant
Responses are generated using AI and may contain mistakes.