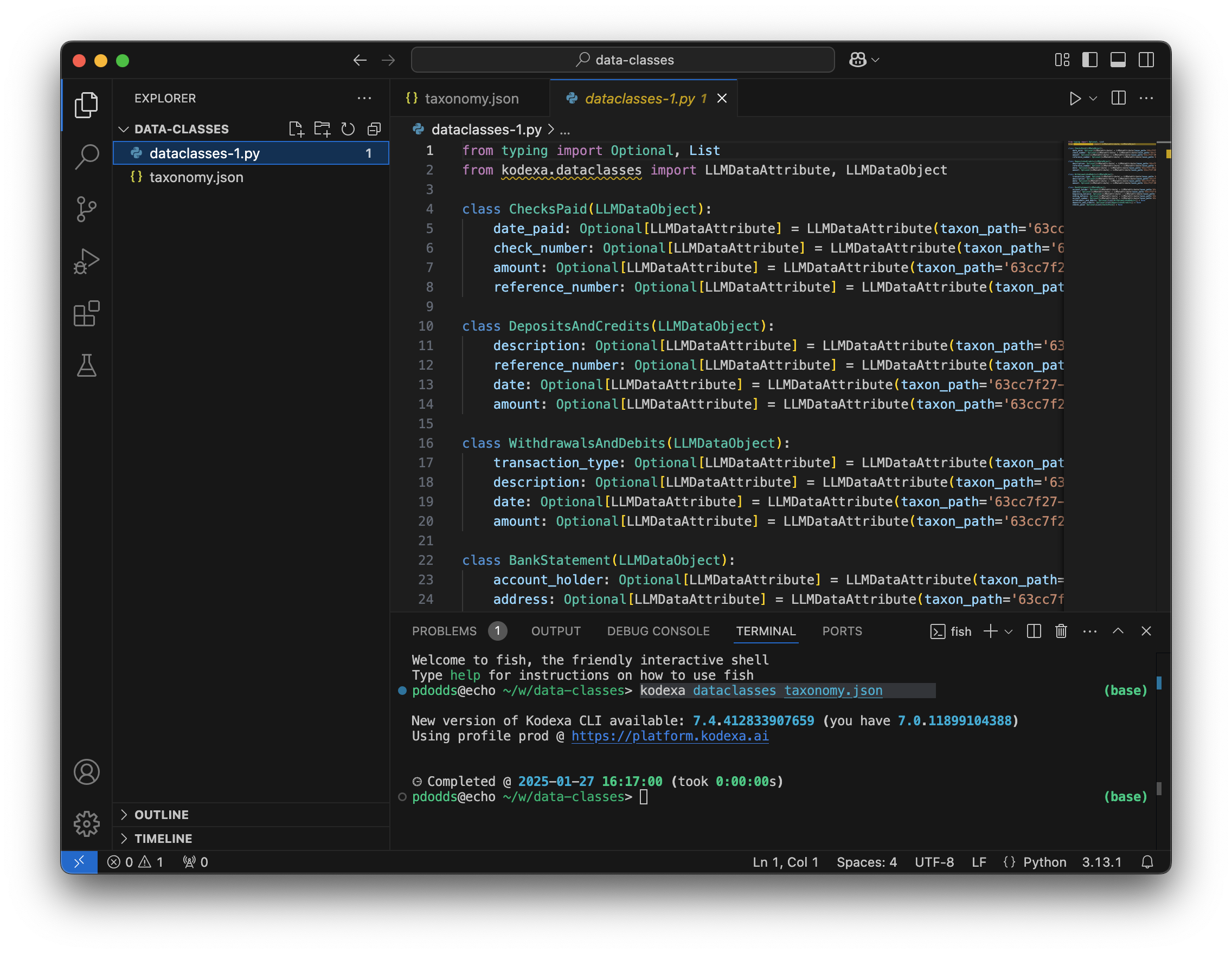
pip install kodexa.
If you go to your project and find the Data Definition used by your LLM model, Developer Tools gives you a copy action for the JSON representation of that definition.
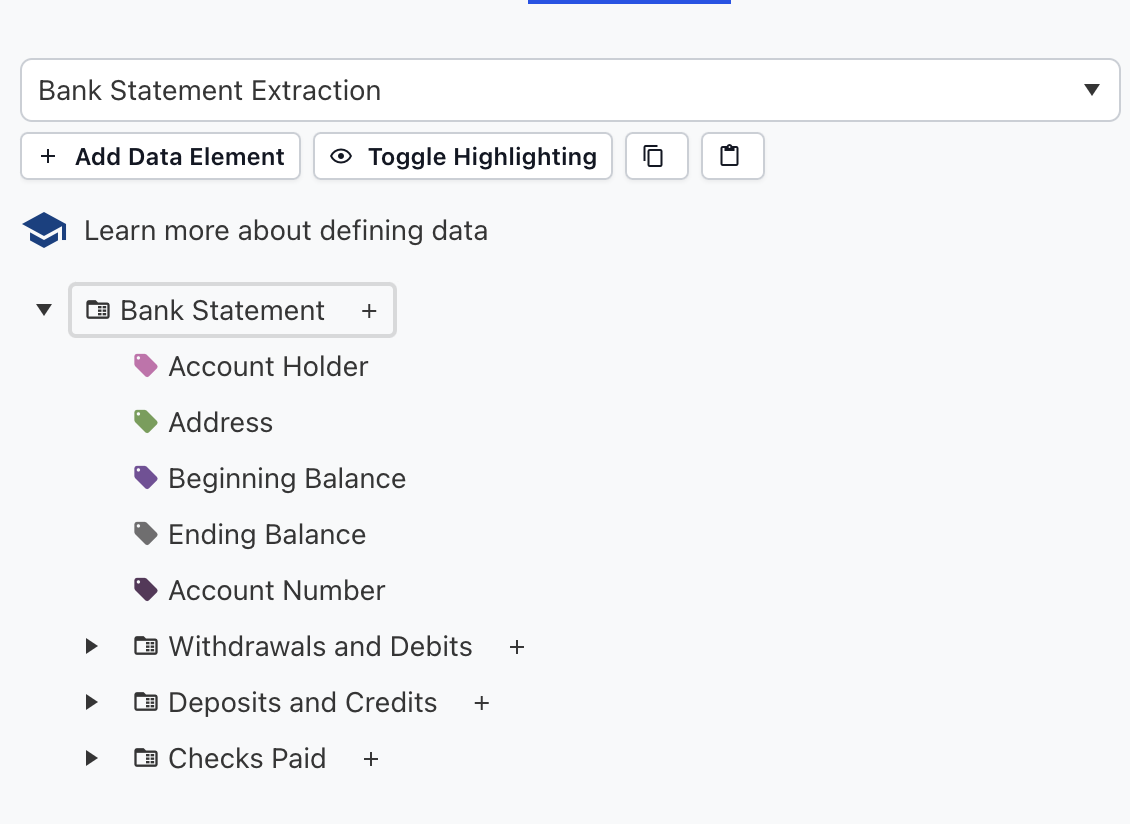
data-definition.json.
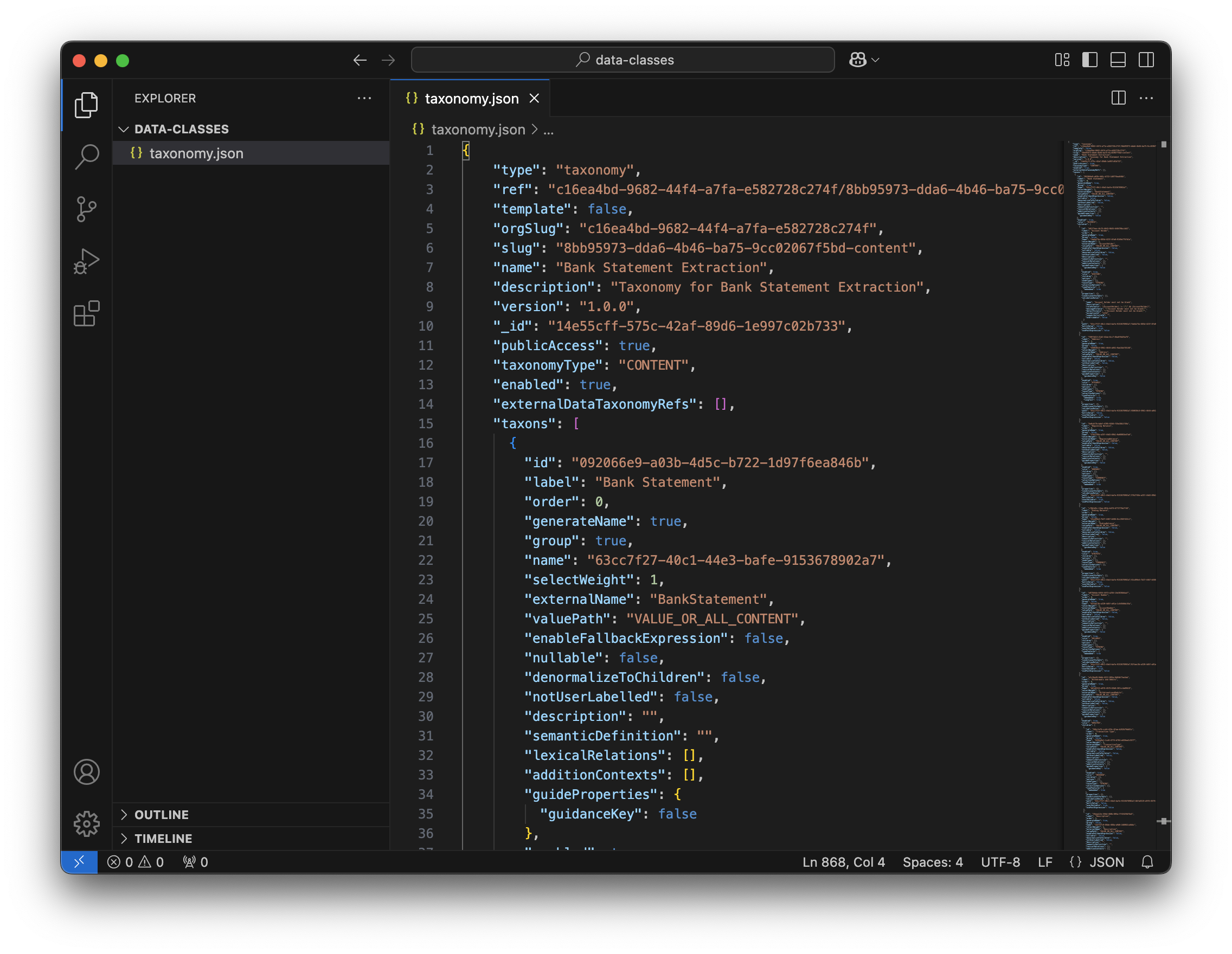
dataclasses.py file that will contain the structure of the objects.